N-mixture modelをStanで実装してみた
Stanで実装するのは一苦労
N-mixtureモデルは二項混合モデルとも呼ばれ,2004年にRoyleが発表したモデルです.このモデルは,個体群が閉鎖している期間内に,空間・時間的に反復計測したカウントデータから検出率を考慮して個体数を推定するものです.詳しくは, BPA本 の12章で紹介されています.
さて,このモデルですが,OpenBUGSやJagsで実装するのはわりと簡単なのですが,Stanで実装しようとすると結構めんどくさいです.
なぜかというと,Stanは 離散値パラメータが使えないからです.局所個体数を周辺化消去しなくてはなりません.これを実装しているネット記事を日本語で見たことないのでやってみたいと思います.仮想データやJagsコードは,BPA本とそのJagsコードをそのまま拝借させてもらいました.
仮装データの生成
200サイトで3回の反復計測をした場合を想定します.
library(rstan) # 標本サイズ R = 200 T = 3 # パラメータ lambda = 5 # 平均個体数 p = 0.5 # 検出率 # 局所個体数 set.seed(1234) N <- rpois(n = R, lambda = lambda) # 計測値データの生成 y <- array(NA, dim = c(R, T)) for (j in 1:T) { y[,j] <- rbinom(n = R, size = N, prob = p) }
モデル
モデルは,Jagsだと簡単でこんな感じです.
model {
# Priors
lambda ~ dgamma(0.005, 0.005) # Standard vague prior for lambda
p ~ dunif(0, 1)
# Likelihood
# Biological model for true abundance
for (i in 1:R) {
N[i] ~ dpois(lambda)
# Observation model for replicated counts
for (j in 1:T) {
y[i,j] ~ dbin(p, N[i])
} # j
} # i
}
このJagsコードのは潜在変数である局所個体数を表しますが,離散値であるためStanでは推定できません.したがって,
を周辺化消去 (場合の数を数え上げ消去し対数尤度を計算する) ことで対処します.周辺化消去については,松浦さんの本(アヒル本)に詳しく書かれているので参考にしてください.以下もこの本に習って書かせていただきました.
をある地点
の全観測(今回なら
)とする時の,この地点のみの尤度を考えます.
はすべての非負整数値を取る可能性があるため,尤度は以下のようになります.
は,
の確率密度の総乗としています.さて,場合の数は無限個あるため,すべてを数え上げることはできません.しかし,
の最大値が例えば9の場合(
),
についてはせいぜい100個体くらいまで考慮すればよさそうです.さらに,
の場合には,
は0になるため,その項を省きます.また,
の上限(十分大きい値,100個体とか)を
としたときに,(1)式を整理すると尤度は以下になります.
実装に必要な対数尤度は,(2)式の対数を取って,Stanのlog_sum_exp 関数を使うと以下のように表現できます.
この対数尤度を観測地点の個数 (R個) に拡張するためには,単に地点数分for 文で繰り返せばいいだけです.
これをStanで書くと以下のようになります.
// Simplest binomial mixture model
data {
int<lower=0> R; // 地点数
int<lower=0> T; // 反復計測数
int<lower=0> y[R, T]; // カウントデータ
int<lower=0> K; // 個体数サイズの上限
}
transformed data {
int<lower=0> max_y[R];
for (i in 1:R)
max_y[i] = max(y[i]); // 地点毎の最大観測個体数
}
parameters {
real<lower=0> lambda; // 平均個体数
real<lower=0,upper=1> p; // 検出率
}
model {
// 事前分布
lambda ~ cauchy(0, 10);
// p ~ beta(1, 1); // としてもOK
// Likelihood
for (i in 1:R) {
vector[K - max_y[i] + 1] lp; // 地点毎の尤度
for (j in 1:(K - max_y[i] + 1))
lp[j] = poisson_lpmf(max_y[i] + j - 1 | lambda)
+ binomial_lpmf(y[i] | max_y[i] + j - 1, p);
target += log_sum_exp(lp);
}
}
transformed dataブロックとmodelブロックでy[i]としていますが,このアクセスは配列y[R, T]のi番目の行をrow_vectorとして取り出す操作です.
実装
set.seed(123) ## Parameters monitored params <- c("lambda", "p") ## MCMC settings ni <- 1000 nt <- 1 nb <- 500 nc <- 4 ## Initial values inits <- lapply(1:nc, function(i) list(p = runif(1, 0, 1), lambda = runif(1, 0, 1))) ## Call Stan from R out <- stan("stanmodel.stan", data = list(y = y, R = R, T = T, K = 100), init = inits, pars = params, chains = nc, iter = ni, warmup = nb, thin = nt, seed = 1, open_progress = FALSE)
推定結果を見てみると,
| parameter | mean | se_mean | sd | 2.5% | 25% | 50% | 75% | 97.5% | n_eff | Rhat |
|---|---|---|---|---|---|---|---|---|---|---|
| lambda | 4.899 | 0.016 | 0.328 | 4.352 | 4.672 | 4.857 | 5.091 | 5.661 | 442 | 1.007 |
| p | 0.522 | 0.001 | 0.031 | 0.450 | 0.503 | 0.526 | 0.543 | 0.577 | 461 | 1.009 |
| lp__ | -1032.718 | 0.039 | 1.011 | -1035.463 | -1033.146 | -1032.396 | -1031.999 | -1031.738 | 678 | 1.003 |
いい感じに推定できています.
個体数Nの近似計算
これでStanを使って,N-mixtureモデルを実装することができましたが,一つ問題があります.周辺化消去したことによってが消えてしまいました...
しかし,generated quantitiesブロックを工夫することで,近似的に個体数を計算することができます!
以下の実装は,Stan Forumsのこのページを参考にしました.
dataブロックからmodelブロックまでは前のモデルをそのままコピペしています.
// Simplest binomial mixture model
data {
int<lower=0> R; // 地点数
int<lower=0> T; // 反復計測数
int<lower=0> y[R, T]; // カウントデータ
int<lower=0> K; // 個体数サイズの上限
}
transformed data {
int<lower=0> max_y[R];
for (i in 1:R)
max_y[i] = max(y[i]); // 地点毎の最大観測個体数
}
parameters {
real<lower=0> lambda; // 平均個体数
real<lower=0,upper=1> p; // 検出率
}
model {
// 事前分布
lambda ~ cauchy(0, 10);
// p ~ beta(1, 1); // としてもOK
// Likelihood
for (i in 1:R) {
vector[K - max_y[i] + 1] lp; // 地点毎の尤度
for (j in 1:(K - max_y[i] + 1))
lp[j] = poisson_lpmf(max_y[i] + j - 1 | lambda)
+ binomial_lpmf(y[i] | max_y[i] + j - 1, p);
target += log_sum_exp(lp);
}
}
generated quantities{
int Est_N[R];
for(i in 1:R){
vector[K - max_y[i] + 1] lik_binom;
vector[K - max_y[i] + 1] lik_poiss;
vector[K - max_y[i] + 1] lik;
vector[K - max_y[i] + 1] probs;
int ks[K - max_y[i] + 1];
int ki;
for (j in 1:(K - max_y[i] + 1)){
ks[j] = max_y[i] + j - 1;
lik_binom[j] = exp(binomial_lpmf(max_y[i] | max_y[i] + j - 1, p));
lik_poiss[j] = exp(poisson_lpmf(max_y[i] + j- 1| lambda))
/ (exp(poisson_lccdf(max_y[i] + j - 1| lambda)) - exp(poisson_lcdf(K | lambda)));
lik[j] = lik_binom[j]*lik_poiss[j];
}//j
probs = lik/sum(lik);
ki = categorical_rng(probs);
Est_N[i] = ks[ki];
}//i
}
詳細は省きますが,カテゴリカル分布の乱数を使って近似的に計算しています.
JagsとStanの推定性能を比較した図を示します.
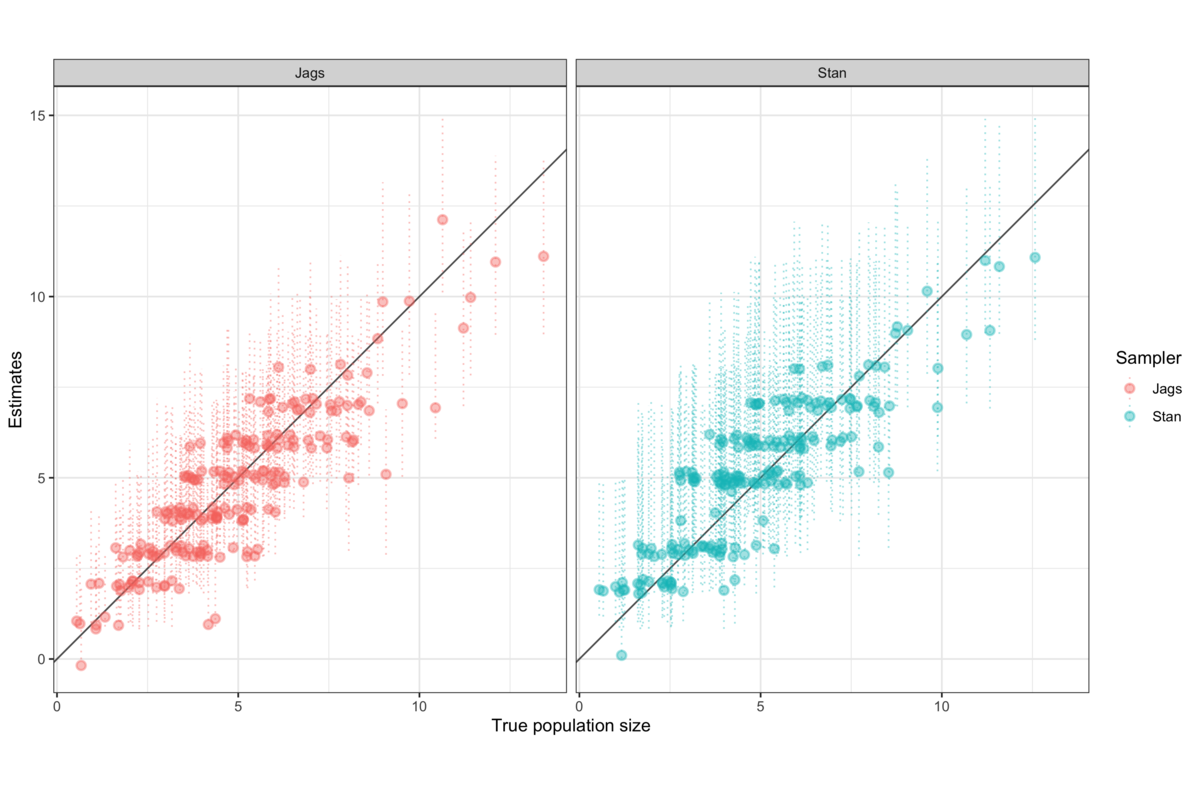 横軸に真の個体数,縦軸に推定された個体数をプロットしました.点線は推定された個体数の95%確信区間を表します.Jagsは97.5%が事後分布に真の値を含み,Stanは99.5%が事後分布に真の値を含んでいます.両方ともうまく推定できていると思います.
横軸に真の個体数,縦軸に推定された個体数をプロットしました.点線は推定された個体数の95%確信区間を表します.Jagsは97.5%が事後分布に真の値を含み,Stanは99.5%が事後分布に真の値を含んでいます.両方ともうまく推定できていると思います.